Go语言基础之结构体
类型别名和自定义类型
自定义类型
在Go语言中有一些基本的数据类型,如string、整型、浮点型、布尔等数据类型, Go语言中可以使用 type 关键字来定义自定义类型。
自定义类型是定义了一个全新的类型。我们可以基于内置的基本类型定义,也可以通过struct定义。例如:
//将MyInt定义为int类型
type MyInt int
通过type关键字的定义,MyInt就是一种新的类型,它具有int的特性。
类型别名
类型别名是Go1.9版本添加的新功能。
类型别名规定:TypeAlias只是Type的别名,本质上TypeAlias与Type是同一个类型。就像一个孩子小时候有小名、乳名,上学后用学名,英语老师又会给他起英文名,但这些名字都指的是他本人。
type TypeAlias = Type
我们之前见过的rune和byte就是类型别名,他们的定义如下:
type byte = uint8
type rune = int32
类型定义和类型别名的区别
类型别名与类型定义表面上看只有一个等号的差异,我们通过下面的这段代码来理解它们之间的区别。
//类型定义
type NewInt int
//类型别名
type MyInt = int
func main() {
var a NewInt
var b MyInt
fmt.Printf("type of a:%T\n", a) //type of a:main.NewInt
fmt.Printf("type of b:%T\n", b) //type of b:int
}
结果显示a的类型是 main.NewInt,表示main包下定义的 NewInt 类型。b的类型是 int。MyInt 类型只会在代码中存在,编译完成时并不会有 MyInt 类型。
结构体
Go语言中的基础数据类型可以表示一些事物的基本属性,但是当我们想表达一个事物的全部或部分属性时,这时候再用单一的基本数据类型明显就无法满足需求了,Go语言提供了一种自定义数据类型,可以封装多个基本数据类型,这种数据类型叫结构体,英文名称struct。 也就是我们可以通过struct来定义自己的类型了。
Go语言中通过struct来实现面向对象。
结构体的定义
使用type和struct关键字来定义结构体,具体代码格式如下:
type 类型名 struct {
字段名 字段类型
字段名 字段类型
…
}
其中:
- 类型名:标识自定义结构体的名称,在同一个包内不能重复。
- 字段名:表示结构体字段名。结构体中的字段名必须唯一。
- 字段类型:表示结构体字段的具体类型。
举个例子,我们定义一个Person(人)结构体,代码如下:
type person struct {
name string
city string
age int8
}
同样类型的字段也可以写在一行:
type person1 struct {
name, city string
age int8
}
这样我们就拥有了一个person的自定义类型,它有name、city、age三个字段,分别表示姓名、城市和年龄。这样我们使用这个person结构体就能够很方便的在程序中表示和存储人信息了。
语言内置的基础数据类型是用来描述一个值的,而结构体是用来描述一组值的。比如一个人有名字、年龄和居住城市等,本质上是一种聚合型的数据类型。
结构体实例化
只有当结构体实例化时,才会真正地分配内存。也就是必须实例化后才能使用结构体的字段。
结构体本身也是一种类型,我们可以像声明内置类型一样使用var关键字声明结构体类型。
var 结构体实例 结构体类型
基本实例化
举个例子:
type person struct {
name string
city string
age int8
}
func main() {
var p1 person
p1.name = "沙河娜扎"
p1.city = "北京"
p1.age = 18
fmt.Printf("p1=%v\n", p1) //p1={沙河娜扎 北京 18}
fmt.Printf("p1=%#v\n", p1) //p1=main.person{name:"沙河娜扎", city:"北京", age:18}
}
我们通过.来访问结构体的字段(成员变量),例如 p1.name 和 p1.age 等。
匿名结构体
在定义一些临时数据结构等场景下还可以使用匿名结构体。
package main
import (
"fmt"
)
func main() {
var user struct{Name string; Age int}
user.Name = "小王子"
user.Age = 18
fmt.Printf("%#v\n", user)
}
创建指针类型结构体
我们还可以通过使用new关键字对结构体进行实例化,得到的是结构体的地址。 格式如下:
var p2 = new(person)
fmt.Printf("%T\n", p2) //*main.person
fmt.Printf("p2=%#v\n", p2) //p2=&main.person{name:"", city:"", age:0}
从打印的结果中我们可以看出p2是一个结构体指针。
需要注意的是在Go语言中支持对结构体指针直接使用.来访问结构体的成员。
var p2 = new(person)
p2.name = "小王子"
p2.age = 28
p2.city = "上海"
fmt.Printf("p2=%#v\n", p2) //p2=&main.person{name:"小王子", city:"上海", age:28}
取结构体的地址实例化
使用&对结构体进行取地址操作相当于对该结构体类型进行了一次new实例化操作。
p3 := &person{}
fmt.Printf("%T\n", p3) //*main.person
fmt.Printf("p3=%#v\n", p3) //p3=&main.person{name:"", city:"", age:0}
p3.name = "七米"
p3.age = 30
p3.city = "成都"
fmt.Printf("p3=%#v\n", p3) //p3=&main.person{name:"七米", city:"成都", age:30}
p3.name = "七米"其实在底层是(*p3).name = "七米",这是Go语言帮我们实现的语法糖。
结构体初始化
没有初始化的结构体,其成员变量都是对应其类型的零值。
type person struct {
name string
city string
age int8
}
func main() {
var p4 person
fmt.Printf("p4=%#v\n", p4) //p4=main.person{name:"", city:"", age:0}
}
使用键值对初始化
使用键值对对结构体进行初始化时,键对应结构体的字段,值对应该字段的初始值。
p5 := person{
name: "小王子",
city: "北京",
age: 18,
}
fmt.Printf("p5=%#v\n", p5) //p5=main.person{name:"小王子", city:"北京", age:18}
也可以对结构体指针进行键值对初始化,例如:
p6 := &person{
name: "小王子",
city: "北京",
age: 18,
}
fmt.Printf("p6=%#v\n", p6) //p6=&main.person{name:"小王子", city:"北京", age:18}
当某些字段没有初始值的时候,该字段可以不写。此时,没有指定初始值的字段的值就是该字段类型的零值。
p7 := &person{
city: "北京",
}
fmt.Printf("p7=%#v\n", p7) //p7=&main.person{name:"", city:"北京", age:0}
使用值的列表初始化
初始化结构体的时候可以简写,也就是初始化的时候不写键,直接写值:
p8 := &person{
"沙河娜扎",
"北京",
28,
}
fmt.Printf("p8=%#v\n", p8) //p8=&main.person{name:"沙河娜扎", city:"北京", age:28}
使用这种格式初始化时,需要注意:
- 必须初始化结构体的所有字段。
- 初始值的填充顺序必须与字段在结构体中的声明顺序一致。
- 该方式不能和键值初始化方式混用。
结构体内存布局
结构体占用一块连续的内存。
type test struct {
a int8
b int8
c int8
d int8
}
n := test{
1, 2, 3, 4,
}
fmt.Printf("n.a %p\n", &n.a)
fmt.Printf("n.b %p\n", &n.b)
fmt.Printf("n.c %p\n", &n.c)
fmt.Printf("n.d %p\n", &n.d)
输出:
n.a 0xc0000a0060
n.b 0xc0000a0061
n.c 0xc0000a0062
n.d 0xc0000a0063
空结构体
空结构体是不占用空间的。
var v struct{}
fmt.Println(unsafe.Sizeof(v)) // 0
构造函数
Go语言的结构体没有构造函数,我们可以自己实现。 例如,下方的代码就实现了一个person的构造函数。 因为struct是值类型,如果结构体比较复杂的话,值拷贝性能开销会比较大,所以该构造函数返回的是结构体指针类型。
func newPerson(name, city string, age int8) *person {
return &person{
name: name,
city: city,
age: age,
}
}
调用构造函数
p9 := newPerson("张三", "沙河", 90)
fmt.Printf("%#v\n", p9) //&main.person{name:"张三", city:"沙河", age:90}
方法和接收者
Go语言中的方法(Method)是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者(Receiver)。接收者的概念就类似于其他语言中的this或者 self。
方法的定义格式如下:
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {
函数体
}
其中:
- 接收者变量:接收者中的参数变量名在命名时,官方建议使用接收者类型名称首字母的小写,而不是
self、this之类的命名。例如,Person类型的接收者变量应该命名为p,Connector类型的接收者变量应该命名为c等。 - 接收者类型:接收者类型和参数类似,可以是指针类型和非指针类型。
- 方法名、参数列表、返回参数:具体格式与函数定义相同。
举个例子:
//Person 结构体
type Person struct {
name string
age int8
}
//NewPerson 构造函数
func NewPerson(name string, age int8) *Person {
return &Person{
name: name,
age: age,
}
}
//Dream Person做梦的方法
func (p Person) Dream() {
fmt.Printf("%s的梦想是学好Go语言!\n", p.name)
}
func main() {
p1 := NewPerson("小王子", 25)
p1.Dream()
}
方法与函数的区别是,函数不属于任何类型,方法属于特定的类型。
指针类型的接收者
指针类型的接收者由一个结构体的指针组成,由于指针的特性,调用方法时修改接收者指针的任意成员变量,在方法结束后,修改都是有效的。这种方式就十分接近于其他语言中面向对象中的this或者self。 例如我们为Person添加一个SetAge方法,来修改实例变量的年龄。
// SetAge 设置p的年龄
// 使用指针接收者
func (p *Person) SetAge(newAge int8) {
p.age = newAge
}
调用该方法:
func main() {
p1 := NewPerson("小王子", 25)
fmt.Println(p1.age) // 25
p1.SetAge(30)
fmt.Println(p1.age) // 30
}
值类型的接收者
当方法作用于值类型接收者时,Go语言会在代码运行时将接收者的值复制一份。在值类型接收者的方法中可以获取接收者的成员值,但修改操作只是针对副本,无法修改接收者变量本身。
// SetAge2 设置p的年龄
// 使用值接收者
func (p Person) SetAge2(newAge int8) {
p.age = newAge
}
func main() {
p1 := NewPerson("小王子", 25)
p1.Dream()
fmt.Println(p1.age) // 25
p1.SetAge2(30) // (*p1).SetAge2(30)
fmt.Println(p1.age) // 25
}
什么时候应该使用指针类型接收者
- 需要修改接收者中的值
- 接收者是拷贝代价比较大的大对象
- 保证一致性,如果有某个方法使用了指针接收者,那么其他的方法也应该使用指针接收者。
任意类型添加方法
在Go语言中,接收者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法。 举个例子,我们基于内置的int类型使用type关键字可以定义新的自定义类型,然后为我们的自定义类型添加方法。
//MyInt 将int定义为自定义MyInt类型
type MyInt int
//SayHello 为MyInt添加一个SayHello的方法
func (m MyInt) SayHello() {
fmt.Println("Hello, 我是一个int。")
}
func main() {
var m1 MyInt
m1.SayHello() //Hello, 我是一个int。
m1 = 100
fmt.Printf("%#v %T\n", m1, m1) //100 main.MyInt
}
注意事项: 非本地类型不能定义方法,也就是说我们不能给别的包的类型定义方法。
结构体的匿名字段
结构体允许其成员字段在声明时没有字段名而只有类型,这种没有名字的字段就称为匿名字段。
//Person 结构体Person类型
type Person struct {
string
int
}
func main() {
p1 := Person{
"小王子",
18,
}
fmt.Printf("%#v\n", p1) //main.Person{string:"北京", int:18}
fmt.Println(p1.string, p1.int) //北京 18
}
**注意:**这里匿名字段的说法并不代表没有字段名,而是默认会采用类型名作为字段名,结构体要求字段名称必须唯一,因此一个结构体中同种类型的匿名字段只能有一个。
嵌套结构体
一个结构体中可以嵌套包含另一个结构体或结构体指针,就像下面的示例代码那样。
//Address 地址结构体
type Address struct {
Province string
City string
}
//User 用户结构体
type User struct {
Name string
Gender string
Address Address
}
func main() {
user1 := User{
Name: "小王子",
Gender: "男",
Address: Address{
Province: "山东",
City: "威海",
},
}
fmt.Printf("user1=%#v\n", user1)//user1=main.User{Name:"小王子", Gender:"男", Address:main.Address{Province:"山东", City:"威海"}}
}
嵌套匿名字段
上面user结构体中嵌套的Address结构体也可以采用匿名字段的方式,例如:
//Address 地址结构体
type Address struct {
Province string
City string
}
//User 用户结构体
type User struct {
Name string
Gender string
Address //匿名字段
}
func main() {
var user2 User
user2.Name = "小王子"
user2.Gender = "男"
user2.Address.Province = "山东" // 匿名字段默认使用类型名作为字段名
user2.City = "威海" // 匿名字段可以省略
fmt.Printf("user2=%#v\n", user2) //user2=main.User{Name:"小王子", Gender:"男", Address:main.Address{Province:"山东", City:"威海"}}
}
当访问结构体成员时会先在结构体中查找该字段,找不到再去嵌套的匿名字段中查找。
嵌套结构体的字段名冲突
嵌套结构体内部可能存在相同的字段名。在这种情况下为了避免歧义需要通过指定具体的内嵌结构体字段名。
//Address 地址结构体
type Address struct {
Province string
City string
CreateTime string
}
//Email 邮箱结构体
type Email struct {
Account string
CreateTime string
}
//User 用户结构体
type User struct {
Name string
Gender string
Address
Email
}
func main() {
var user3 User
user3.Name = "沙河娜扎"
user3.Gender = "男"
// user3.CreateTime = "2019" //ambiguous selector user3.CreateTime
user3.Address.CreateTime = "2000" //指定Address结构体中的CreateTime
user3.Email.CreateTime = "2000" //指定Email结构体中的CreateTime
}
结构体字段的可见性
结构体中字段大写开头表示可公开访问,小写表示私有(仅在定义当前结构体的包中可访问)。
结构体与JSON序列化
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。JSON键值对是用来保存JS对象的一种方式,键/值对组合中的键名写在前面并用双引号""包裹,使用冒号:分隔,然后紧接着值;多个键值之间使用英文,分隔。
//Student 学生
type Student struct {
ID int
Gender string
Name string
}
//Class 班级
type Class struct {
Title string
Students []Student
}
func main() {
c := &Class{
Title: "101",
Students: make([]Student, 0, 200),
}
for i := 0; i < 10; i++ {
stu := Student{
Name: fmt.Sprintf("stu%02d", i),
Gender: "男",
ID: i,
}
c.Students = append(c.Students, stu)
}
//JSON序列化:结构体-->JSON格式的字符串
data, err := json.Marshal(c)
if err != nil {
fmt.Println("json marshal failed")
return
}
fmt.Printf("json:%s\n", data)
//JSON反序列化:JSON格式的字符串-->结构体
str := `{"Title":"101","Students":[{"ID":0,"Gender":"男","Name":"stu00"},{"ID":1,"Gender":"男","Name":"stu01"},{"ID":2,"Gender":"男","Name":"stu02"},{"ID":3,"Gender":"男","Name":"stu03"},{"ID":4,"Gender":"男","Name":"stu04"},{"ID":5,"Gender":"男","Name":"stu05"},{"ID":6,"Gender":"男","Name":"stu06"},{"ID":7,"Gender":"男","Name":"stu07"},{"ID":8,"Gender":"男","Name":"stu08"},{"ID":9,"Gender":"男","Name":"stu09"}]}`
c1 := &Class{}
err = json.Unmarshal([]byte(str), c1)
if err != nil {
fmt.Println("json unmarshal failed!")
return
}
fmt.Printf("%#v\n", c1)
}
- json.Marshal:结构体–>JSON格式的字符串
- json.Unmarshal:JSON格式的字符串–>结构体
结构体标签(Tag)
Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来。 Tag在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
`key1:"value1" key2:"value2"`
结构体tag由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。同一个结构体字段可以设置多个键值对tag,不同的键值对之间使用空格分隔。
注意事项: 为结构体编写Tag时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在key和value之间添加空格。
例如我们为Student结构体的每个字段定义json序列化时使用的Tag:
//Student 学生
type Student struct {
ID int `json:"id"` //通过指定tag实现json序列化该字段时的key
Gender string //json序列化是默认使用字段名作为key
name string //私有不能被json包访问
}
func main() {
s1 := Student{
ID: 1,
Gender: "男",
name: "沙河娜扎",
}
data, err := json.Marshal(s1)
if err != nil {
fmt.Println("json marshal failed!")
return
}
fmt.Printf("json str:%s\n", data) //json str:{"id":1,"Gender":"男"}
}
结构体和方法补充知识点
因为slice和map这两种数据类型都包含了指向底层数据的指针,因此我们在需要复制它们时要特别注意。我们来看下面的例子:
type Person struct {
name string
age int8
dreams []string
}
func (p *Person) SetDreams(dreams []string) {
p.dreams = dreams
}
func main() {
p1 := Person{name: "小王子", age: 18}
data := []string{"吃饭", "睡觉", "打豆豆"}
p1.SetDreams(data)
// 你真的想要修改 p1.dreams 吗?
data[1] = "不睡觉"
fmt.Println(p1.dreams) // ?
}
正确的做法是在方法中使用传入的slice的拷贝进行结构体赋值。
func (p *Person) SetDreams(dreams []string) {
p.dreams = make([]string, len(dreams))
copy(p.dreams, dreams)
}
同样的问题也存在于返回值slice和map的情况,在实际编码过程中一定要注意这个问题。
Go结构体的内存布局
结构体的内存布局
结构体大小
结构体是占用一块连续的内存,一个结构体变量的大小是由结构体中的字段决定。
type Foo struct {
A int8 // 1 个字节
B int8 // 1 个字节
C int8 // 1 个字节
}
var f Foo
fmt.Println(unsafe.Sizeof(f)) // 3
内存对齐
但是结构体的大小又不完全由结构体的字段决定,例如:
type Bar struct {
x int32 // 4
y *Foo // 8
z bool // 1
}
var b1 Bar
fmt.Println(unsafe.Sizeof(b1)) // 24
有的同学可能会认为结构体变量b1的内存布局如下图所示,那么问题来了,结构体变量b1的大小怎么会是24呢?
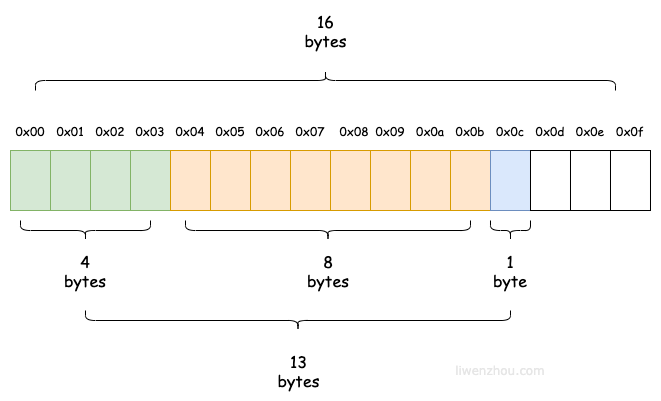
很显然结构体变量b1的内存布局和上图中的并不一致,实际上的布局应该如下图所示,灰色虚线的部分就是内存对齐时的填充(padding)部分。
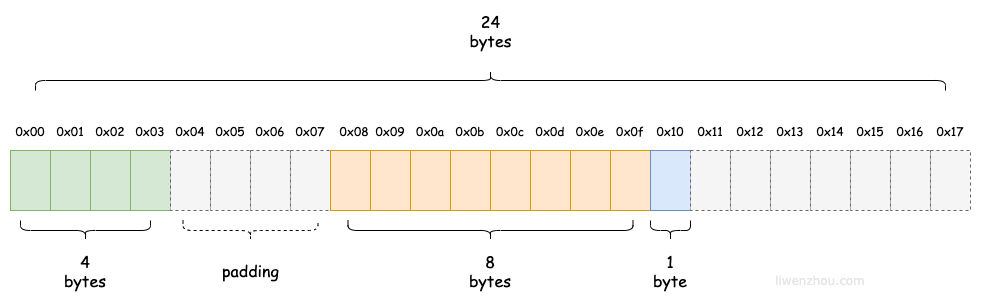
Go 在编译的时候会按照一定的规则自动进行内存对齐。之所以这么设计是为了减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。如果不进行内存对齐的话,很可能就会增加CPU访问内存的次数。例如下图中CPU想要获取b1.y字段的值可能就需要两次总线周期。
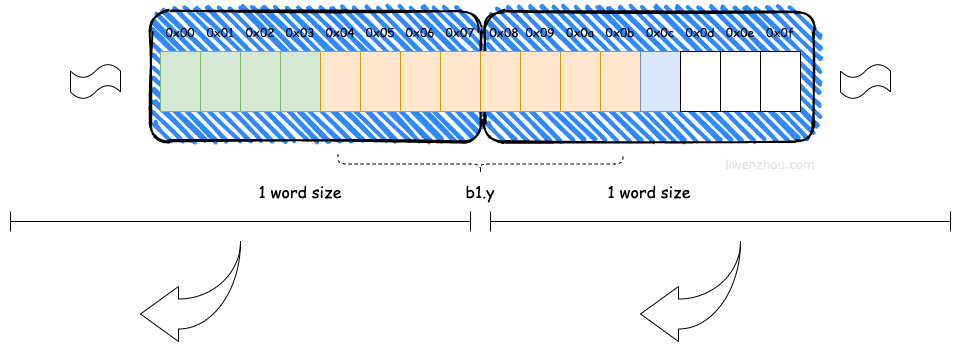
因为 CPU 访问内存时,并不是逐个字节访问,而是以字(word)为单位访问。比如 64位CPU的字长(word size)为8bytes,那么CPU访问内存的单位也是8字节,每次加载的内存数据也是固定的若干字长,如8words(64bytes)、16words(128bytes)等。
对齐保证
我们上面已经知道了可以通过内置unsafe包的Sizeof函数来获取一个变量的大小,此外我们还可以通过内置unsafe包的Alignof函数来获取一个变量的对齐系数,例如:
// 结构体变量b1的对齐系数
fmt.Println(unsafe.Alignof(b1)) // 8
// b1每一个字段的对齐系数
fmt.Println(unsafe.Alignof(b1.x)) // 4:表示此字段须按4的倍数对齐
fmt.Println(unsafe.Alignof(b1.y)) // 8:表示此字段须按8的倍数对齐
fmt.Println(unsafe.Alignof(b1.z)) // 1:表示此字段须按1的倍数对齐
unsafe.Alignof()的规则如下:
- 对于任意类型的变量 x ,
unsafe.Alignof(x)至少为 1。 - 对于 struct 类型的变量 x,计算 x 每一个字段 f 的
unsafe.Alignof(x.f),unsafe.Alignof(x)等于其中的最大值。 - 对于 array 类型的变量 x,
unsafe.Alignof(x)等于构成数组的元素类型的对齐倍数。
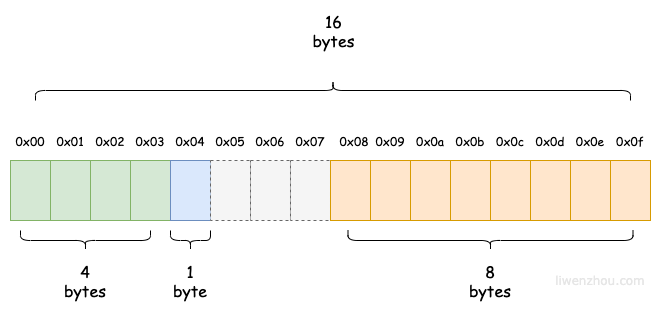
在了解了上面的规则之后,我们就可以通过调整结构体 Bar 中字段的顺序来减少其大小:
type Bar2 struct {
x int32 // 4
z bool // 1
y *Foo // 8
}
var b2 Bar2
fmt.Println(unsafe.Sizeof(b2)) // 16
此时结构体 Bar2 变量的内存布局示意图如下:
或者将字段顺序调整为以下顺序。
type Bar3 struct {
z bool // 1
x int32 // 4
y *Foo // 8
}
var b3 Bar3
fmt.Println(unsafe.Sizeof(b3)) // 16
此时结构体 Bar3 变量的内存布局示意图如下:
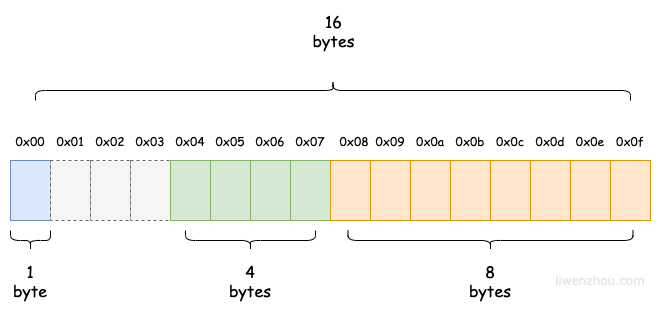
总结一下:在了解了Go的内存对齐规则之后,我们在日常的编码过程中,完全可以通过合理地调整结构体的字段顺序,从而优化结构体的大小。
结构体内存布局的特殊场景
除了上述利用内存对齐规则调整字段顺序优化结构体内存布局外,关于Go语言中结构体的内存布局还存在以下几种相对特殊的场景需要注意。
空结构体字段对齐
首先我们需要了解的一个前提是:如果结构或数组类型不包含大小大于零的字段(或元素),则其大小为0。两个不同的0大小变量在内存中可能有相同的地址。
由于空结构体struct{}的大小为 0,所以当一个结构体中包含空结构体类型的字段时,通常不需要进行内存对齐。例如:
type Demo1 struct {
m struct{} // 0
n int8 // 1
}
var d1 Demo1
fmt.Println(unsafe.Sizeof(d1)) // 1
但是当空结构体类型作为结构体的最后一个字段时,如果有指向该字段的指针,那么就会返回该结构体之外的地址。为了避免内存泄露会额外进行一次内存对齐。
type Demo2 struct {
n int8 // 1
m struct{} // 0
}
var d2 Demo2
fmt.Println(unsafe.Sizeof(d2)) // 2
示意图:
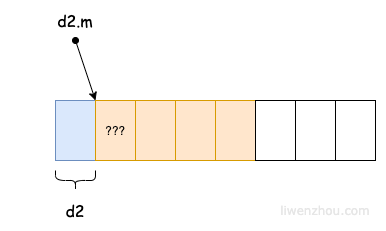
在实际编程中通过灵活应用空结构体大小为0的特性能够帮助我们节省很多不必要的内存开销。
例如,我们可以使用空结构体作为map的值来实现一个类似 Set 的数据结构。
var set map[int]struct{}
我们还可以使用空结构体作为通知类channel的元素,例如Go源码src/cmd/internal/base/signal.go中。
// src/cmd/internal/base/signal.go
// Interrupted is closed when the go command receives an interrupt signal.
var Interrupted = make(chan struct{})
以及 src/net/pipe.go中都有类似的使用示例。
// src/net/pipe.go
// pipeDeadline is an abstraction for handling timeouts.
type pipeDeadline struct {
mu sync.Mutex // Guards timer and cancel
timer *time.Timer
cancel chan struct{} // Must be non-nil
}
原子操作在32位平台要求强制内存对齐
在 x86 平台上原子操作需要强制内存对齐是因为在 32bit 平台下进行 64bit 原子操作要求必须 8 字节对齐,否则程序会 panic,下面是Go源码src/atomic/doc.go中的说明。
// src/atomic/doc.go
// BUG(rsc): On 386, the 64-bit functions use instructions unavailable before the Pentium MMX.
//
// On non-Linux ARM, the 64-bit functions use instructions unavailable before the ARMv6k core.
//
// On ARM, 386, and 32-bit MIPS, it is the caller's responsibility
// to arrange for 64-bit alignment of 64-bit words accessed atomically.
// The first word in a variable or in an allocated struct, array, or slice can
// be relied upon to be 64-bit aligned.
这里可以参照groupcache库中的实际应用,示例代码如下。
type Group struct {
name string
getter Getter
peersOnce sync.Once
peers PeerPicker
cacheBytes int64 // limit for sum of mainCache and hotCache size
// mainCache is a cache of the keys for which this process
// (amongst its peers) is authoritative. That is, this cache
// contains keys which consistent hash on to this process's
// peer number.
mainCache cache
// hotCache contains keys/values for which this peer is not
// authoritative (otherwise they would be in mainCache), but
// are popular enough to warrant mirroring in this process to
// avoid going over the network to fetch from a peer. Having
// a hotCache avoids network hotspotting, where a peer's
// network card could become the bottleneck on a popular key.
// This cache is used sparingly to maximize the total number
// of key/value pairs that can be stored globally.
hotCache cache
// loadGroup ensures that each key is only fetched once
// (either locally or remotely), regardless of the number of
// concurrent callers.
loadGroup flightGroup
_ int32 // force Stats to be 8-byte aligned on 32-bit platforms
// Stats are statistics on the group.
Stats Stats
}
// ...
// Stats are per-group statistics.
type Stats struct {
Gets AtomicInt // any Get request, including from peers
CacheHits AtomicInt // either cache was good
PeerLoads AtomicInt // either remote load or remote cache hit (not an error)
PeerErrors AtomicInt
Loads AtomicInt // (gets - cacheHits)
LoadsDeduped AtomicInt // after singleflight
LocalLoads AtomicInt // total good local loads
LocalLoadErrs AtomicInt // total bad local loads
ServerRequests AtomicInt // gets that came over the network from peers
}
Group结构体中通过添加一个int32字段强制让Stats字段在32bit平台也是8字节对齐的。
fasle sharing
结构体内存对齐除了上面的场景外,在一些需要防止CacheLine伪共享的时候,也需要进行特殊的字段对齐。例如sync.Pool中就有这种设计:
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
结构体中的pad字段就是为了防止false sharing而设计的。
当不同的线程同时读写同一个cache line上不同数据时就可能发生false sharing。false sharing会导致多核处理器上严重的系统性能下降。具体的可以参考 伪共享(False Sharing)。
如注释所说这里之所以使用128字节进行内存对齐是为了兼容更多的平台。
hot path
hot path 是指执行非常频繁的指令序列。
在访问结构体的第一个字段时,我们可以直接使用结构体的指针来访问第一个字段(结构体变量的内存地址就是其第一个字段的内存地址)。
如果要访问结构体的其他字段,除了结构体指针外,还需要计算与第一个值的偏移(calculate offset)。在机器码中,偏移量是随指令传递的附加值,CPU 需要做一次偏移值与指针的加法运算,才能获取要访问的值的地址。因为访问第一个字段的机器代码更紧凑,速度更快。
下面的代码是标准库sync.Once中的使用示例,通过将常用字段放置在结构体的第一个位置上减少CPU要执行的指令数量,从而达到更快的访问效果。
// src/sync/once.go
// Once is an object that will perform exactly one action.
//
// A Once must not be copied after first use.
type Once struct {
// done indicates whether the action has been performed.
// It is first in the struct because it is used in the hot path.
// The hot path is inlined at every call site.
// Placing done first allows more compact instructions on some architectures (amd64/386),
// and fewer instructions (to calculate offset) on other architectures.
done uint32
m Mutex
}
- Author: 未来可期
- Link: http://shansec.github.io/post/%E5%9F%BA%E7%A1%80/Go%E8%AF%AD%E8%A8%80%E5%9F%BA%E7%A1%80%E4%B9%8B%E7%BB%93%E6%9E%84%E4%BD%93/
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.